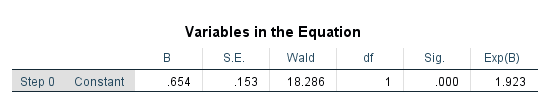Logistic Regression is a supervised learning technique, which is used to understand the relationship between a dependent variable and one or more independent variables. Logistic regression is conducted by estimating the probabilities and by using the logistic regression equation.
Assumptions
1. Logistic regression requires the dependent variable to be binary, i.e., 0 and 1.
2. Logistic regression requires the observations to be independent of each other.
3. No Multicollinearity is assumed among the independent variables.
4. Linearity of independent variables and log odds is assumed.
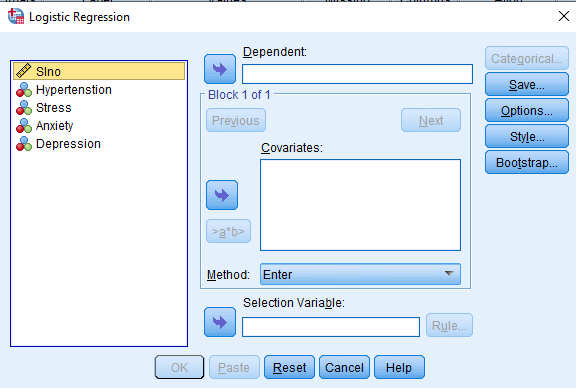
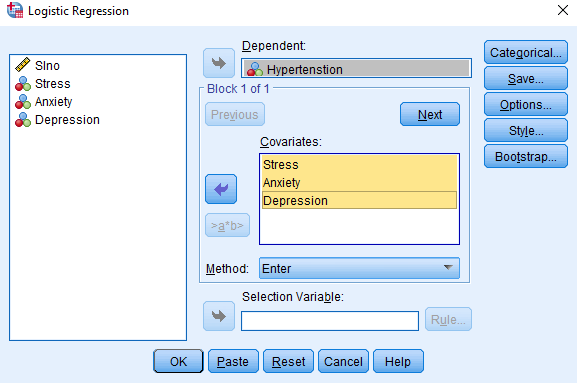
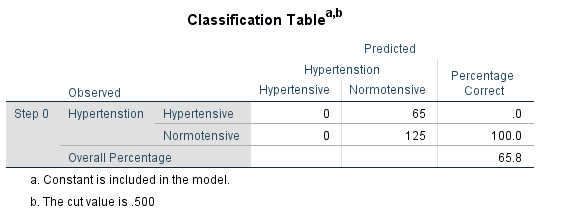
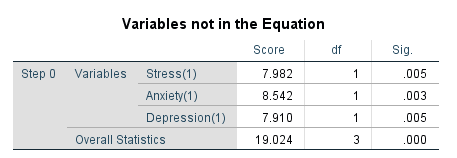
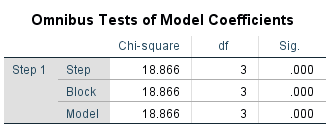
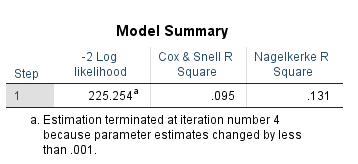
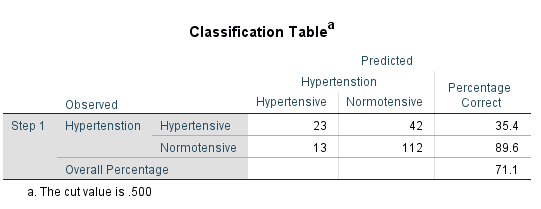
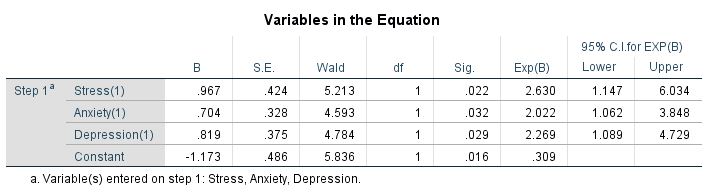
Here, we have taken Hypertension as a dependent variable and we have considered Stress, Anxiety and Depression as the independent variables.
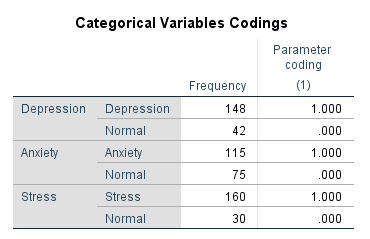
In the dependent variable (Hypertension), we labelled 0 as ‘Hypertensive’ and 1 as ‘Normotensive’. In the independent variables (Stress, Anxiety and Depression), we labelled 0 as ‘Stress’ and 1 as ‘Normal’, 0 as ‘Anxiety’ and 1 as ‘Normal’, and 0 as ‘Depression’ and 1 as ‘Normal’.
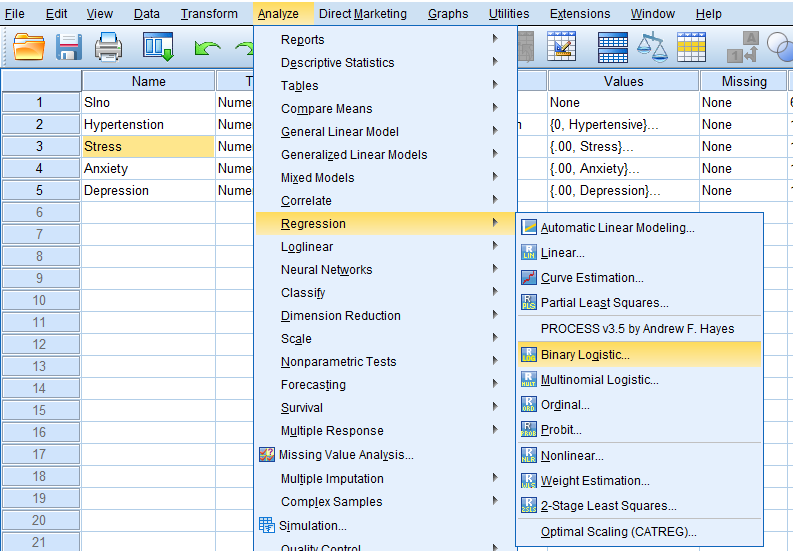
In SPSS, Logistic Regression is found in Analyze > Regression > Binary Logistic Regression